In dit hoofdstuk onderzoeken we de bivariate relatie tussen twee continue variabelen in R. We gaan in op de covariantie, de correlatie, en de bivariate lineaire regressieanalyse.
We beginnen dit overzicht met het laden van relevante R packages (‘libraries’). Deze packages zijn reeds geïnstalleerd op de universitaire computers, maar moeten eerst geladen worden. Als je op je eigen computer werkt, moet je de packages eerst installeren via install.packages() (zie Appendix B voor het overzicht van packages om te installeren). De dataset die we gebruiken bevat informatie over de politieke en economische karakteristieken van landen over de hele wereld. De dataset (demdata.rds) is beschikbaar op Brightspace samen met het codeboek.
#Packageslibrary(rio) #laden van datalibrary(sjPlot) #overzichten van data objectenlibrary(tidyverse) #data manipulatie en grafiekenlibrary(modelsummary) #creëren van correlatietabellen#Datademdata <-import("demdata.rds") |>as_tibble()
1
We converteren onze dataset onmiddellijk naar een ‘tibble’. Dit is niet nodig maar geeft ons een beter overzicht. Zie Statistiek I, 2.1.
Waarschuwing
Maak gebruik van een R project folder om je data files, scripts en opdrachten in te bewaren. Dit maakt werken met R een stuk gemakkelijker. Hoe je dit doet wordt beschreven in Statistiek I, 1.5. Wanneer je data inlaadt, doe dit dan niet door te dubbelklikken op het bestand op je computer, maar gebruik hiervoor de import() syntax uit het rio package. Zie Paragraaf A.1.2.
1.1 Ter herinnering: data objecten
We kunnen de inhoud van een data object op verschillende manieren bekijken. Vaak gaat een dataset gepaard met een codeboek dat we kunnen inkijken, maar we kunnen ook data verder inspecteren met R. We kunnen bijvoorbeeld gewoon de naam van het data object (hier: ‘demdata’) typen om vervolgens de inhoud te printen. De ‘tibble’ transformatie maakt dit overzichtelijker:
De ‘tibble’ transformatie maakt de output duidelijker. We zien nu een overzicht van de eerste variabelen in de dataset (de kolommen) en de eerste observaties (rijen).
We zouden ook de voorkeur kunnen geven aan een overzicht van alle variabelen in de dataset en hun kenmerken (‘attributes’). In Statistiek 1 (zie hier) werd hiervoor de str() functie gebruikt. Hier gebruiken we glimpse() als een vereenvoudigde manier om dit te doen. Het resultaat is een overzicht van alle 41 variabelen in de dataset. We doen dit hier voor een verkorte versie van de dataset om minder lange output te verkrijgen.
#Een kleinere dataset door selectie van beperkt aantal variabelendemdata_sub <- demdata |>select(v2x_egaldem, TypeSoc2005, HDI2005, TYPEDEMO1984, gini_2019)glimpse(demdata_sub)
Ten slotte kunnen we de view_df() functie gebruiken uit het sjPlot package om de namen van alle variabelen te zien, hun labels (indien van toepassing), de mogelijke waarden voor deze variabelen en de labels van deze waarden (indien van toepassing). De informatie wordt in het Viewer venster (standaard rechtsonder) weergegeven. Als je klikt op “Show in new window” krijg je een grotere weergave in een tab van je browser.
view_df(demdata_sub)
Data frame: demdata_sub
ID
Name
Label
Values
Value Labels
1
v2x_egaldem
range: 0.0-0.9
2
TypeSoc2005
Type of human development, (3-cat, classified from
HDI) (UNDP 2008)
1
2
3
Low human development
Medium human development
High human development
3
HDI2005
Human Development Index (HDI), 2005 100-pt scale
(UNDP 2007)
range: 0.3-1.0
4
TYPEDEMO1984
Type of democracy, 1984
1
2
Autocracies
Democracies
5
gini_2019
range: 22.6-48.0
Output uitleg
view_df() creëert output met de volgende kolommen:
Name: Naam van de variabele
Label: Label van de variabele, indien aanwezig in de dataset. Doorgaans een korte inhoudelijke beschrijving van de variabele.
Values: Indien de variabele continu is vind je hier het minimum en maximum van de variabele in de dataset “range: X-X”. Bijvoorbeeld, de v2x_egaldem variabele reikt van 0 tot 0.9. Indien de variabele slechts enkele discrete waarden bevat, worden deze getoond (zie bv. TypeSoc2005).
Value Labels: Sommige variabelen hebben labels voor de specifieke waarden die ze aannemen. Dit label beschrijft waar de cijferwaarde voor staat. Bijvoorbeeld, observaties met een 1 voor TYPEDEMO1984 zijn autocratieën en observaties die een 2 scoren zijn democratieën.
Waarschuwing!
view_df() is een handige functie om een overzicht van je dataset te hebben, maar als je dataset veel variabelen heeft wordt veel output geproduceerd. Voeg dus view_df(data) niet toe aan je R Markdown (.rmd) bestand wanneer je je taak inlevert. Gebruik de functie voor jezelf, maar verwijder dan deze syntax om je ingeleverde taak overzichtelijk te houden.
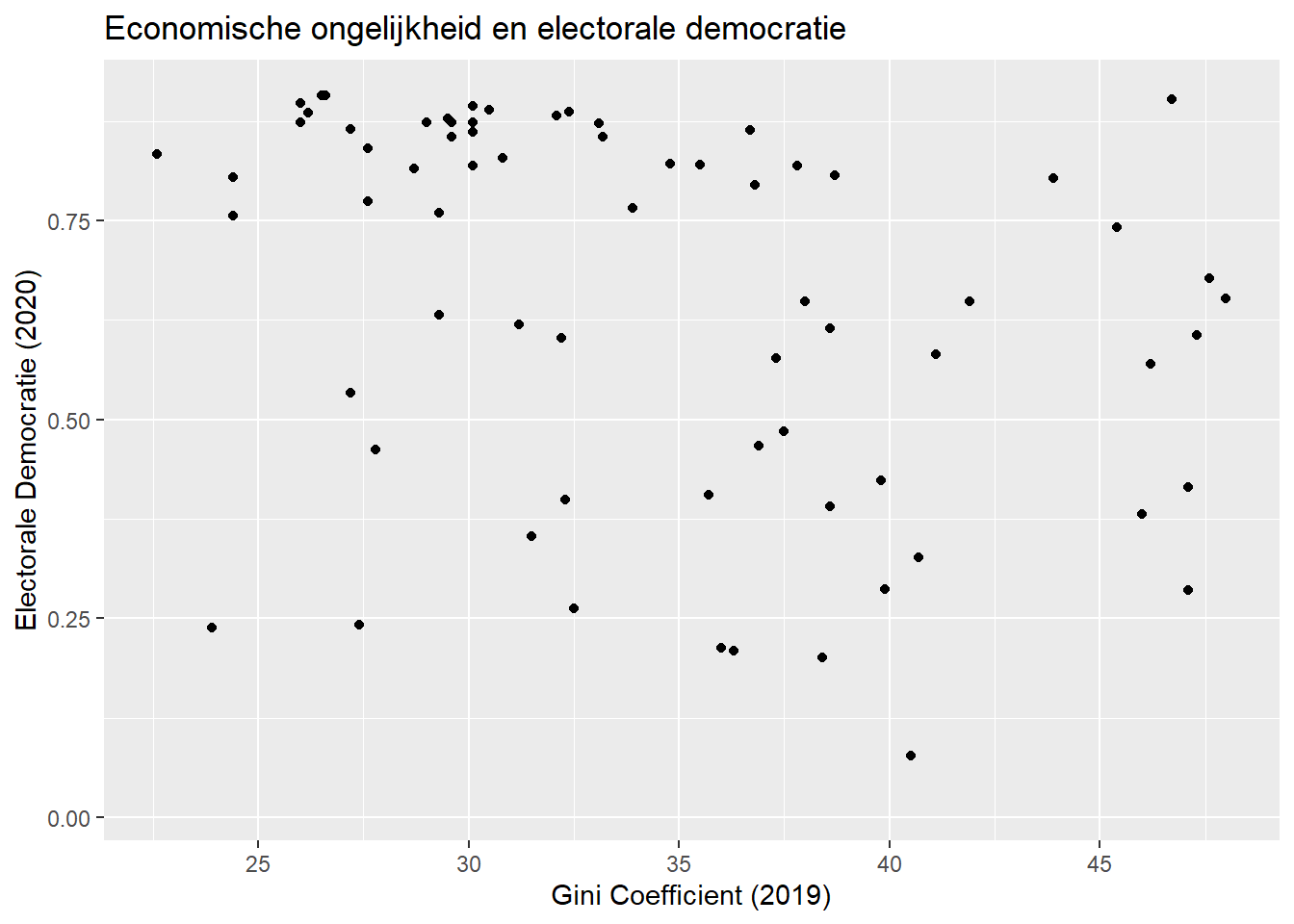
1.2 Visualisatie met een scatterplot
In ons voorbeeld onderzoeken we de relatie tussen economische ongelijkheid en het niveau van electorale democratie in landen.
De variabele gini_2019 meet het niveau van economische ongelijkheid en heeft waarden tussen 0 en 100 (hogere waarden = meer ongelijkheid).1 De variabele v2x_polyarchy meet het niveau van electorale democratie in een land. De variabele is continue met een bereik tussen 0 en 1. Hogere waarden betekenen een hoger niveau van democratie.
We kunnen de relatie tussen deze twee continue variabelen onderzoeken met behulp van een scatterplot. Zie Hoofdstuk 8 in het Statistiek I boek voor meer informatie over ggplot(), ook over de opties om plots mooier te maken.
ggplot(demdata, aes(x=gini_2019, y=v2x_polyarchy)) +geom_point() +labs(title ="Economische ongelijkheid en electorale democratie", x ="Gini Coefficient (2019)", y ="Electorale Democratie (2020)") +scale_x_continuous(breaks=seq(from=25, to=45, by=5))
Warning: Removed 109 rows containing missing values or values outside the scale range
(`geom_point()`).
Output uitleg
De output bevat een waarschuwing: “Warning: Removed 109 rows containing missing values (`geom_point()`).”. Dit is geen reden tot zorg en komt voor omdat er observaties zijn die geen waarden hebben voor een van de variabelen of beide variabelen. Jammer genoeg geeft R wel meer waarschuwingen die weinig belang hebben.
Zo lees je bovenstaande syntax:
ggplot(
Hier vertellen we R dat we de data willen plotten met behulp van het ggplot2 package, onderdeel van het tidyverse package.
demdata
Dit is de naam van het data object waaruit we variabelen willen plotten. Deze naam verander je naar je eigen dataset.
aes(x=gini_2019, y=v2x_polyarchy)
Hier vertellen we R hoe de grafiek eruit moet zien (aes= “aesthetic mapping”). We plaatsen “gini_2019” op de x-as en “v2x_polyarchy” op de y-as. Het is gebruikelijk om de afhankelijke variabele op de y-as en de onafhankelijke variabele op de x-as te plaatsen.
geom_point()
Hier bepalen we welk plot we willen, namelijk een puntenwolk (‘point’). Elk punt op de grafiek geeft een observatie in de dataset weer. De positie van de observatie wordt bepaald door de waarden op onze twee variabelen.
Hier vragen we R om de x-as te laten lopen van 25 tot 45 (in lijn met de geobserveerde waarden voor gini_2019 in de dataset) en om de 5 waarden een aanduiding te maken op de as. Dit verduidelijkt de visualisatie.2
Waarschuwing!
In dit voorbeeld hebben we de schaal van de x-as aangepast om een duidelijkere weergave te bekomen. Dit is niet altijd nodig, de standaard optie waarbij deze syntax-regel wordt weggelaten produceert vaak al goede resultaten. Let er ook op dat je deze syntax niet gewoon overneemt, zeker als de variabele die je op de x-as wil plotten anders geschaald is (bv. van 0 tot 10). Dit kan anders vreemde resultaten opleveren. Denk eraan bij het overnemen van syntax uit dit boek: copy, paste, en update.
Zie Paragraaf 8.2 voor verdere instructies over het maken van duidelijke scatterplots en richtlijnen om een plot te beschrijven.
1.3 Covariantie
In bovenstaande figuur zagen we meer landen in de linkerbovenhoek dan in de linkeronderhoek, en meer lagere waarden voor electorale democratie naarmate we hogere waarden voor gini 2019 zien. Dit lijkt te wijzen op een negatieve relatie: landen met lage ongelijkheid scoren doorgaans hoog op democratie.
Nu gebruiken we de covariantie statistiek om de relatie tussen onze twee variabelen duidelijker te vatten en onze interpretatie van bovenstaande figuur te verifiëren. We maken gebruik van de cov() functie in R. Deze functie is ingebouwd in R en kunnen we gebruiken zonder extra packages te laden.
We nemen “gini_2019” als x-variabele en “v2x_polyarchy” als y-variabele in lijn met ons scatterplot. De covariantiestatistiek is echter symmetrisch en we zouden dezelfde uitkomst verkrijgen als we de variabelen zouden omdraaien.
cov(x = demdata$gini_2019, y = demdata$v2x_polyarchy,use ="complete.obs")
[1] -0.560385
De syntax betekent het volgende:
cov(
De naam van de functie. Deze wordt toegepast op de variabelen gespecificeerd tussen de haakjes.
x = demdata$gini_2019,
Verduidelijkt dat we de “gini_2019” variabele uit het data object “demdata” als x-variabele willen we beschouwen.
y = demdata$v2x_polyarchy,
Verduidelijkt dat we de “v2x_polyarchy” variabele uit het data object “demdata” als y-variabele willen we beschouwen.
use= "complete.obs")
Hier verduidelijken we dat we enkel observaties met non-missing waarden in de berekening willen meenemen.
De covariantie is -0.56. Dit is in lijn met onze interpretatie van het scatterplot. Er is een negatieve relatie tussen onze variabelen, hogere waarden voor ongelijkheid zijn doorgaans geassocieerd met lagere waarden voor democratie.
1.4 Correlaties
We kunnen ook de correlatiecoëfficiënt gebruiken om de relatie tussen onze continue variabelen te onderzoeken. De correlatie is een gestandaardiseerde maatstaf in tegenstelling tot de covariantie.
Er bestaan meerdere correlatiecoëfficiënten. Doorgaans gebruiken we de Pearson correlatiecoëfficiënt voor continue variabelen (vaak aangeduid met een schuine letter r: \(r\)). We maken gebruik van de cor.test() functie, die ingebouwd is in R.3 Ook de correlatie is een symmetrische maatstaf. Je krijgt dus dezelfde uitkomst wanneer je de x en y-variabelen zou omdraaien.
cor.test(x = demdata$gini_2019, y = demdata$v2x_polyarchy, method ="pearson")
Pearson's product-moment correlation
data: demdata$gini_2019 and demdata$v2x_polyarchy
t = -3.0433, df = 68, p-value = 0.003325
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.5374741 -0.1211040
sample estimates:
cor
-0.3462257
Zo lees je de syntax:
cor.test(
De naam van de functie. Deze wordt toegepast op de variabelen gespecificeerd tussen de haakjes.
x = demdata$gini_2019
Verduidelijkt dat we de “gini_2019” variabele uit het data object “demdata” als x-variabele willen we beschouwen.
y = demdata$v2x_polyarchy
Verduidelijkt dat we de “v2x_polyarchy” variabele uit het data object “demdata” als y-variabele willen we beschouwen.
method = "pearson")
Vertelt R dat we de Pearson correlatiecoëfficiënt willen gebruiken. We kunnen een andere methode vragen door bijvoorbeeld “method = spearman” te typen.
Output uitleg
In R toont de output het volgende:
‘t =’: de t-waarde of t-statistiek van de correlatie
‘df =’: de vrijheidsgraden (‘degrees of freedom’)
‘p-value =’: de p-waarde voor de schatting (i.e., de kans dat we deze of een grotere t-waarde zouden uitkomen als de nulhypothese (correlatiecoëfficënt is in werkelijkheid gelijk aan 0) waar zou zijn en de assumpties van het model correct zijn).
‘95 percent confidence interval:’: het 95% betrouwbaarheidsinterval voor de correlatiecoëfficiënt
‘cor’: de correlatiecoëfficiënt
De correlatiecoëfficiënt is hier -0.35 (afgerond op 2 decimalen). Hoe interpreteren we dit cijfer?
Interpretatie
Correlatiecoëfficiënten liggen tussen -1 en +1, waarbij:
-1 = een perfect negatieve lineaire relatie. Alle observaties vallen op een neerwaarts lopende lijn in een scatterplot.
0 = geen lineaire relatie
+1 = een perfect positieve lineaire relatie. Alle observaties vallen op een opwaarts lopende lijn in een scatterplot.
Een positieve relatie houdt in dat 1 variabele stijgt als de andere stijgt. Een negatieve relatie betekent dat 1 variabele verwacht wordt te dalen als de andere variabele stijgt.
Correlatiecoëfficiënten geven naast de richting ook de sterkte van een relatie aan. De volgende vuistregels, gebaseerd op Cohen (1988), worden vaak gebruikt:
r \(<\) 0.1: Heel klein
0.1 \(<=\) 0.3: Klein
0.3 \(<=\) 0.5: Gemiddeld
r \(>=\) 0.5: Groot
In ons voorbeeld is de correlatie gemiddeld.
Ten slotte: De bovenstaande vuistregels helpen bij het interpreteren van de correlatiecoëfficiënt (en zijn voldoende voor dit vak). Besprekingen in papers moeten doorgaans diepgaander zijn (bv. sterk in vergelijking met andere studies, andere effecten enz.).
Cohen, Jacob. 1988. Statistical power analysis for the behavioral sciences. 2nd dr. Hillsdale, NJ: Erlbaum Associates.
1.5 Bivariate lineaire regressie
De laatste manier waarop we de bivariate relatie tussen twee continue (interval/ratio) variabelen kunnen onderzoeken is met een bivariaat regressiemodel.4.
Hier gebruiken we wederom electorale democratie als afhankelijke variabele en gini als onafhankelijke variabele. In dit geval is welke variabele we als afhankelijke en welke we als onafhankelijke beschouwen sterk bepalend voor het resultaat.
1.5.1 Analyse en output
m1 <-lm(v2x_polyarchy ~ gini_2019, data = demdata)
De syntax lees je als volgt:
m1 <-
We kiezen hier de naam voor ons model: ‘m1’. Dit kun je veranderen voor eigen doeleinden. R zal de resultaten van onze regressieanalyse opslaan in een object met deze naam. In principe hoef je de resultaten niet in een data object op te slaan, maar dit is wel gebruikelijk omdat we de resultaten vaak verder gebruiken en we dan naar dit object kunnen verwijzen.
lm(
Dit is de functie voor lineaire regressie: lm = linear (regression) model.
v2x_polyarchy ~ gini_2019,
De variabele links van de tilde (“~”) is de afhankelijke variabele. Rechts vinden we de onafhankelijke variabele.
data = demdata)
Hier verduidelijken we welke dataset gebruikt wordt (in dit geval demdata). Dit gedeelte komt altijd aan het einde.
Waarschuwing!
Er is een belangrijk verschil tussen cor.test()/cov() enerzijds en lm()anderzijds. Bij de ene kun je de x en y variabelen omwisselen en dezelfde uitkomst verkrijgen, bij lm kan dit niet. De beslissing over welke variabele je afhankelijke is bij lineaire regressie, is dus belangrijk.
We kunnen de resultaten bekijken door de naam van ons model in de console te typen en enter te drukken:
Dit geeft ons de regressiecoëfficiënten voor de constante en de onafhankelijke variabele. De informatie die we krijgen is zeer beperkt.5 Het is gebruikelijker om de output te bekijken met de summary() functie aangezien deze meer informatie geeft:
summary(m1)
Call:
lm(formula = v2x_polyarchy ~ gini_2019, data = demdata)
Residuals:
Min 1Q Median 3Q Max
-0.5389 -0.1502 0.0903 0.1668 0.3965
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.060311 0.136512 7.767 5.8e-11 ***
gini_2019 -0.011859 0.003897 -3.043 0.00333 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2225 on 68 degrees of freedom
(109 observations deleted due to missingness)
Multiple R-squared: 0.1199, Adjusted R-squared: 0.1069
F-statistic: 9.262 on 1 and 68 DF, p-value: 0.003325
Output uitleg
In R toont de output het volgende:
“Call”: Het regressiemodel dat geschat is.
“Residuals”: Informatie over de residuals van het model (behandeld in verdere hoofdstukken).
“Coefficients”: Dit zijn de regressiecoëfficiënten voor het model, waaronder…
Estimate: De coëfficiënt voor elke term in het model. Bv. voor de constante (“(Intercept)” = 1.060311) en de onfahankelijke variabele (“gini_2019” = -0.0118
Std. Error: de standaardfout van de coëfficiënt
t value: De t-waarde of t-statistiek van de coëfficiënt
Pr(>|t|): De p-waarde die bij de t-statistiek hoort. Voor meer informatie, zie Hoofdstuk 3 .
Het onderste gedeelte van de output gaan over de ‘fit’ van het model, behandeld in Hoofdstuk 6 .
De coëfficiënt voor economische ongelijkheid was negatief, net zoals de covariantie en correlatie. Alle drie vatten de statistieken op hun manier de negatieve lineaire relatie tussen de variabelen.
Interpretatie
De Estimate kolom bevat de waarden voor de coëfficiënten van het model:
(Intercept): Wat is de verwachte waarde voor de afhankelijke variabele als de onafhankelijke variabele in het model de waarde 0 aanneemt? Hier vinden we dat bij 0 ongelijkheid, de verwachte democratiescore gelijk is aan 1.06. Het intercept (of de constante) is niet altijd realistisch, bijvoorbeeld wanneer een predictor 0 niet kan aannemen in de praktijk of wanneer de schatting van de afhankelijke het werkelijke bereik ervan overschrijdt (democratiescores gemeten hier hebben een minimum van 0 en een maximum van 1)
Coëfficiënten voor continue onafhankelijke variabelen (bv. gini_2019): De coëfficiënt geeft de verwachte verandering in de afhankelijke variabele Y weer wanneer de onafhankelijke variabele X met 1 eenheid stijgt. Hier zien we dat electorale democratie verwacht wordt met-0.01 punten te dalen als ongelijkheid met 1 punt stijgt. Zie Paragraaf 8.4 voor meer informatie over rapportage in taken en papers.
De coëfficiënt voor gini_2019 is -0.01. Wat wil dit zeggen over de sterkte van het effect? Regressiecoëfficiënten zijn niet gestandaardiseerd zoals de correlatiecoëfficiënt dus zijn er geen vuistregels te hanteren. In latere hoofdstukken bespreken we gestandaardiseerde regressiecoëfficiënten Paragraaf 4.2 en voorspelde waarden Hoofdstuk 5). Deze kunnen helpen bij de interpretatie over de sterkte van het effect, maar (zoals bij de correlatie) zal een bespreking van de sterkte ook in moeten gaan op andere studies, de context etc.
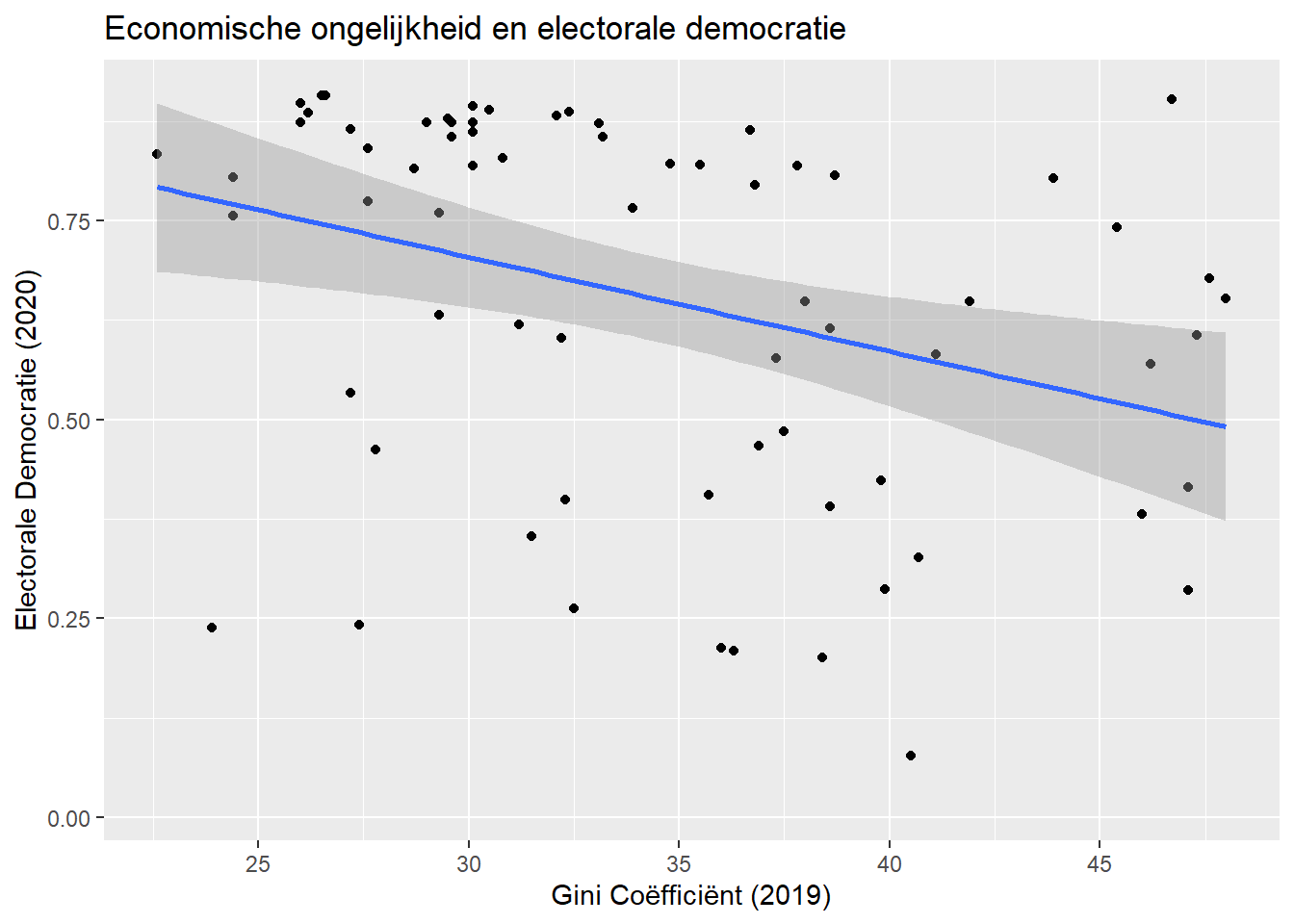
1.5.2 Regressielijn in een scatterplot
De regressielijn wordt vaak toegevoegd aan een scatterplot. Dit kunnen we als volgt doen:
ggplot(demdata, aes(x = gini_2019, y = v2x_polyarchy)) +geom_point() +geom_smooth(method ="lm") +labs(title ="Economische ongelijkheid en electorale democratie", x ="Gini Coëfficiënt (2019)", y ="Electorale Democratie (2020)") +scale_x_continuous(breaks =seq(from =25, to =45, by =5))
`geom_smooth()` using formula = 'y ~ x'
Warning: Removed 109 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 109 rows containing missing values or values outside the scale range
(`geom_point()`).
De syntax is dezelfde als voor ons eerdere scatteplot met één toevoeging:
geom_smooth(method = "lm") +
Hier vragen we R om een lijn toe te voegen die de relatie tussen de twee variabelen weergeeft. We vragen hier specifiek om de lineaire regressielijn via method = "lm". We krijgen een lijn en ook het betrouwbaarheidsinterval voor de schatting in het grijs.
Het theoretische bereik van de variabele is van 0 tot 100, maar in de praktijk observeren we enkel waarden tussen 22.6 en 48.↩︎
Je kunt meer leren over de seq() command als je ?seq() typt in de console en enter tikt.↩︎
Als je meerdere correlatiecoëfficiënten tegelijkertijd wil onderzoeken zou je het correlation package kunnen gebruiken (webpage). Je hebt dit package echter niet nodig voor deze cursus.↩︎
Zoals we verder in de cursus zien kunnen we ook binaire/categorische onafhankelijke variabelen gebruiken om een continue variabele te voorspellen in een lineaire regressie.↩︎
We kunnen de coëfficiënten ook opvragen met de coef() functie. Bijvoorbeeld: “coef(m1)” zou ons ook gewoon de coëfficiënten geven. In verdere hoofdstukken zullen we nog een functie zien om de output te bekijken: de tidy() functie uit het broom package.↩︎