#Packages
library(patchwork) # For combining plots together
library(kableExtra) # For html table making
library(rio) # Importing data
library(tidyverse) # Data management and plotting
library(broom) # Model coefficients
library(performance) # Model and scale performance
library(modelsummary) # Descriptive statistic tables
# Datasets used in examples below
scale_data <- import("scale_data.rda")
hdi_data <- import("hdi_data.csv")Appendix E — Creating Indices / Scales
Who is this for?
You do not need to know how to perform these analyses for the assignments in Statistics II. Instead, this guide is for students writing their final paper in Data Skills or a BAP thesis project.
It can sometimes be a good idea to combine variables together into a single index for use in statistical analyses, whether as one’s dependent variable or as an independent variable. We may wish to explain variation in populist attitudes, for instance, where being a populist is understood as being anti-elitist, believing that public policy should follow the common will, and possessing a manichean (good vs. evil) understanding of political conflict.1 Answering our research question may thus involve combining measurements of these three attributes together to form a final scale for analysis. We may also wish to combine items to obtain a more accurate measurement of a concept. Consider the final exam in Statistics II. We could ask you a single question to assess your statistics knowledge, but doing so would produce a less accurate estimate of how much you have learned in comparison to asking you multiple questions. Finally, combining items together can reduce the complexity of our statistical models and thereby enhance their parsimony; instead of including 10 independent variables, for instance, we might be able to include 5 in total (4 + an index of the remaining ones). This can be useful in situations where independent variables are highly correlated with one another such that including them in a model as separate variables would introduce a high level of multicollinearity into model estimates.
This appendix focuses on how to create indices based on multiple variables and the considerations that arise when doing so. The first section discusses some general considerations guiding the decision to make an index from multiple items. We then provide a worked example where we show how to assess the reliability of an index and then how to create indices either by taking the sum of multiple variables or their average. The second worked example will discuss what to do when the items you want to combine together do not have the same original scaling.
E.1 General Considerations
The R data management steps we demonstrate in the sections below could be used to create an index from all sorts of measurements (variables) in your dataset. Of course, this does not mean that we should just start combining things together without any forethought. Instead, the decision to create an index should proceed in a thoughtful manner guided by broader considerations regarding the background concept and what a valid and reliable measurement of it would look like. We briefly touch on some of these considerations here.2
The natural starting point for our discussions is “conceptualization”. We may wish to empirically study variation in “democracy” or “populism” or “ideology”, etc. However, in order to do so we must come to some understanding of what these concepts mean based on past research and our own reasoning. Otherwise, how would we know what to look for in the first place?
Our next task is identifying appropriate indicators/measures/operationalizations of this concept. Here, we are looking for valid and reliable measurements regardless of whether we are relying on a single item or, in our examples below, an index of multiple indicators to measure our concept. However, this begs the question: What does it mean for an indicator (or scale) to be a valid or reliable measurement?
Validity is a continuous (e.g., measurements can be more less valid) and multi-dimensional (e.g., there are different elements of validity) concept. We would first ask whether a measurement (or scale) has “face” or “content” validity - do the items touch on all (or a representative set of) relevant aspects of the underlying construct we’re interested in measuring? Does it look like the measures actually, well, measure the concept in question? A question asking someone whether they believe that “the people should have the final say on most important political issues” seems a valid measurement of (one aspect of) populist attitudes per the definition above, but not as a measure of “political participation”. Second, we could think about the potential predictive validity of the measure or scale: does it predict things it should (convergent validity) and not predict things it shouldn’t (discriminant validity)? Your judgments on this front will likely rely on the accumulation of available evidence from past research rather than your own attempts to validate a scale or item. In Example 1 below, for instance, we are relying on a large body of research on the nature of emotions which has validated the measurements we will use.
A second consideration is whether our indicators are reliable measurements of the underlying concept. A reliable measurement will consistently produce similar results in similar conditions. A classic example is that of a weight scale: if you place the same object on the scale over and over again, will you get the same weight measurement? You will if the weight scale is reliable. Reliability is not necessarily accuracy though. A weight scale that is always off by 1kg is reliable, but not accurate. We would say that the weight scale in this example produces biased estimates (i.e., systematically wrong estimates).
There are different ways that researchers assess the reliability of a measurement. They may look at test-retest reliability as in the weight scale example above. For instance, we might ask a sample of respondents a series of questions relating to populism and then re-interview them, and re-ask those questions, a few days later. If our measure is reliable then we should see a high correlation between responses on the two interviews (assuming that nothing dramatic has happened in the time between measurements to change the person’s underlying populist attitudes). You will almost certainly rely on other researchers’ efforts on this front. However, there is another way of assessing reliability that is particularly relevant when creating indices: internal reliability. Internal reliability concerns whether multiple items meant to measure an underlying concept “hang together”, i.e., strongly correlate with one another. The more strongly a series of items correlate with one another, the more internally reliable the scale is said to be. We will show you how to assess internal reliability below.
E.2 Example 1: Emotions and Campaign Engagement
E.2.1 Our Data
Why do people engage in electoral campaign activities (e.g., volunteer time or money to a political campaign, attend campaign rallies, etc.)? One prominent account focuses on people’s skills and resources: does the person have the time needed to volunteer, or the money to donate, or various types of civic skills that may facilitate taking action. However, people must also possess the motivation to act as well. Recent work suggests that emotions can play a powerful role in motivating people to take political action.3 We will examine this idea with a subset of data taken from the 2024 American National Election Studies (ANES) as a means of showing how to think about creating an index in R.
The ANES is a social survey of a random sample of American adults. Respondents are first surveyed prior to the national elections in the US (pre-election) and then again right after the election is held (post-election). Respondents on the 2024 version of the survey were asked whether they had undertaken a number of different campaign specific behaviors on the post-election wave of the survey. Respondents were asked the following prompt followed by the questions below (with the name of the variable in the dataset in parentheses): “We would like to find out about some of the things people do to help a party or a candidate win an election. During the campaign…”
- “Did you talk to any people and try to show them why they should vote for or against one of the parties or candidates?” (
persuade) - “Did you participate in any online political meetings, rallies, speeches, fundraisers, or things like that in support of a particular candidate?” (
online_meetings) - “Did you go to any political meetings, rallies, speeches, dinners, or things like that in support of a particular candidate?” (
rallies) - “Did you wear a campaign button, put a campaign sticker on your car, or place a sign in your window or in front of your house?” (
campaign_button) - “Did you do any (other) work for one of the parties or candidates?” (
other_work) - “Did you give any money to a political party during this election year?” (
contribute_money_party) - “Did you give any money to any other group that supported or opposed candidates?” (
contribute_money_group)
Respondents could say “yes” or “no” to these questions. The former response is given a code of 1 and the latter a code of 0.
It is always a good idea to get to know your data before doing any sort of complicated analysis. We will thus use the psych::describe() function to get a quick overview of the descriptive data for these variables with the “mean” column telling us the proportion of respondents completing each action.
scale_data |>
select(persuade:contribute_money_group) |>
psych::describe() |>
select(vars:mean, min, max)- 1
-
Using the
psych::prefix eanbles us to use this function without loading thepsychpackage. We do this because thepsychpackage also contains other functions that conflict withtidyversefunctions. - 2
-
Here we use the
select()function to just show only some of the columns produced bypsych::describe(). These are binary variables so some of the other columns produced by this command (e.g., skew, kurtosis) are less relevant to know about than if these were continuous variables.
vars n mean min max
persuade 1 4957 0.40 0 1
online_meetings 2 4761 0.10 0 1
rallies 3 4959 0.05 0 1
campaign_button 4 4962 0.14 0 1
other_work 5 4962 0.03 0 1
contribute_money_party 6 4760 0.10 0 1
contribute_money_group 7 4760 0.03 0 1Around 40% of respondents reported trying to persuade others about how to vote. At the same time, relatively few people (aprox. 3-14%) reported doing the other types of acts.
The items above will be the source of our dependent variable below. The ANES also asked respondents a battery of questions about their emotions with these questions being asked prior to the election. The questions possess a similar structure: “How [emotion term] do you feel about how things are going in the country?” The specific emotion terms asked about were:
- hopeful
- afraid
- outraged
- angry
- happy
- worried
- proud
- irritated
- nervous
Respondents could choose from one of five response options: not at all (=1), a little (=2), somewhat (=3), very (=4), and extremely (=5). Let’s take a quick look at the descriptive statistics for these variables:
scale_data |>
select(hopeful:nervous) |>
psych::describe() |>
select(vars, n, mean, sd, median, min, max, skew, kurtosis) vars n mean sd median min max skew kurtosis
hopeful 1 4756 2.49 1.11 3 1 5 0.24 -0.69
afraid 2 4757 3.35 1.21 3 1 5 -0.25 -0.84
outraged 3 4752 3.21 1.31 3 1 5 -0.20 -1.03
angry 4 4754 3.23 1.24 3 1 5 -0.17 -0.91
happy 5 4756 2.01 1.01 2 1 5 0.62 -0.46
worried 6 4755 3.58 1.15 4 1 5 -0.41 -0.70
proud 7 4750 2.04 1.06 2 1 5 0.67 -0.44
irritated 8 4753 3.57 1.16 4 1 5 -0.44 -0.68
nervous 9 4758 3.47 1.18 4 1 5 -0.36 -0.73One takeaway from this data is that these survey respondents were not feeling particularly positive about the state of things in the United States. On average, respondents reported feeling more anger, worry, irritation, etc., than hope, happiness, or pride. At the same time, there is a fair degree of variation on all items.
Our goal is to examine the relationship between emotions (independent variable) and campaign engagement (dependent variable). How should we do that?
One thing we could do is perform separate (logistic) models wherein we predict each engagement item with all of the emotions as predictor variables. This is appropriate if our goal is to separately analyze the different behaviors and emotional states, e.g., if we are interested in examining whether the individual emotions have similar relationships with different types of political acts. However, it may make sense to create indices for either the dependent and/or independent variable.
One the one hand, we might not be interested in predicting the individual behaviors but instead in understanding the breadth of campaign activity. Instead of examining whether feeling “proud” leads a person to be more likely to take some particular action, the goal of our paper may be in examining whether this emotion is associated with taking more actions rather than fewer. We will need to combine the items into a single index to accomplish this goal. We will show how to do this below.
On the other hand, we may have theoretical and empirical reasons for combining the emotions items into an index or, perhaps, more than one. Suppose that we regress either an individual campaign behavior item or a campaign engagement index on all of the emotion items at once. This would enable us to see whether there exists a relationship between, say, how “proud” one says they are and campaign engagement after adjusting for the effects of feeling “happy” and “hopeful” on campaign engagement. However, these words capture fairly similar (if not identical) emotional states that may very well go together (e.g,. someone experiencing pride may also experience happiness). Stated somewhat differently, someone feeling positively about the state of things in the US at the time of the election may be likely to report higher values on all three items to communicate their underlying positivity. Let’s take a look at the correlations between the emotion items to see if that intuition has merit:
scale_data |>
select(hopeful:nervous) |>
rename_with(str_to_title) |>
datasummary_correlation()- 1
- Selects just the items we want to produce correlations for.
- 2
-
A shortcut! The column names are in lower case but we wanted them to be uppercase. We could have renamed them manually. But, here we use the
str_to_title()function that is part of thestringrlibrary (part of thetidyverse) to convert the columns to “title case”, which automatically capitalizes the first letter of each word. Hat tip to this StackOverflow thread. - 3
-
Creates a correlation table. This function comes from the
modelsummarypackage. See Chapter 8 for more on this command.
| Hopeful | Afraid | Outraged | Angry | Happy | Worried | Proud | Irritated | Nervous | |
|---|---|---|---|---|---|---|---|---|---|
| Hopeful | 1 | . | . | . | . | . | . | . | . |
| Afraid | -.33 | 1 | . | . | . | . | . | . | . |
| Outraged | -.33 | .64 | 1 | . | . | . | . | . | . |
| Angry | -.34 | .66 | .77 | 1 | . | . | . | . | . |
| Happy | .61 | -.39 | -.41 | -.40 | 1 | . | . | . | . |
| Worried | -.35 | .75 | .66 | .66 | -.42 | 1 | . | . | . |
| Proud | .60 | -.36 | -.39 | -.39 | .72 | -.41 | 1 | . | . |
| Irritated | -.36 | .64 | .72 | .73 | -.44 | .68 | -.42 | 1 | . |
| Nervous | -.31 | .75 | .62 | .64 | -.36 | .75 | -.35 | .64 | 1 |
Table E.1 shows the correlation coefficients for the emotion terms. As expected, “hopeful” is strongly correlated with both “happy” (r = 0.61) and “proud” (r = 0.60). “Happy” and “proud” are likewise strongly correlated with one another (r = 0.72). Table E.1 shows something else important. The other items in the table (e.g., “afraid”, “outraged”, etc.) are positively correlated with one other but negatively correlated with the three positive emotion terms. ANES respondents who said they were angry (etc.) about the current state of affairs in the US tended not to say they were happy, which makes some intuitive sense. This suggests that we may be able to make our regression model simpler (more parsimonious) by creating two indices, one for the “positive” emotions and another for the “negative” emotions. This will help us avoid potential multicollinearity issues.
E.2.2 Checking Scale Reliability
We discussed above how we should think about the validity and reliability of a scale before creating one. We return to these ideas here and show you how to investigate the internal reliability of a proposed index.
Our main concepts are “campaign engagement” and “emotions”. The items described above certainly seem like they have face validity as measures of those concepts. Of course, we could wonder about whether there are additional elements to these concepts not being tapped by these particular measures. For instance, there are likely other types of campaign activities out there and certainly other types of emotions (e.g., disgust, shame, etc.). Does that matter for our eventual conclusions about emotions and campaign engagement? That would be a natural candidate for further discussion in the conclusion of our paper!
The preceding section ended by discussing the possibility of creating two emotion indices: one for the “positive” and one for the “negative” emotion items. Is that a reasonable decision? On this front, we could justify our decision in part based on existing work in this area and specifically a prominent theoretical model of emotions called “affective intelligence theory” which argues that human cognition and behavior is supported by two emotional systems. Not coincidentally, these items are included in the ANES to help test this broader theoretical perspective.4 In your examples you would perhaps also be able to justify your decision to combine items in relation to existing work and your efforts to clearly conceptualize the concept(s) at the heart of your paper.
What about reliability? Would creating an index of the “positive” emotion items yield an internally reliable index, for instance? We can begin investigating this question by considering the inter-correlations between the various items of a proposed scale, much as we did above. These analyses suggest that a scale of the positive, and one for the negative, emotion terms would be reliable given the strong correlations between items seen in Table E.1. While examining the inter-relationships between items via an investigation of their correlation coefficients is a good start, there are nevertheless two complications in making a final judgment based purely on that information: (1) there may be lots of correlations to consider and (2) how do we know if the inter-correlations are strong enough to justify creating an index?
On this front, researchers creating an index will typically report a summary measure of scale reliability known as Cronbach’s alpha (\(\alpha\)). The calculation of \(\alpha\) is based in part on the average degree of covariance between the various items in the scale.5 The \(\alpha\) measure ranges from 0-1 with higher values indicating a more reliable index. A score of 0 would essentially indicate that the items are unrelated to one another while a score of 1 would indicate perfect correlation between all of the items. Researchers often use the following rules of thumb when interpreting \(\alpha\) scores:
- \(\geq\) 0.90: Excellent reliability
- 0.80-0.89: Good reliability
- 0.70-0.79: Acceptable reliability
- 0.60-0.69: Questionable reliability
- < 0.60: Poor reliability
A proposed index with a \(\alpha\) below 0.6 is generally considered a poor candidate for creation. However, we note an important caveat here. While one can calculate an \(\alpha\) score for an index comprised of binary indicators, this will generally lead to under-estimates of reliability because \(\alpha\) assumes interval/continuous data. There are more advanced methods for investigating the reliability of indices based on binary data, but they go belond the scope of this book.
We can obtain the \(\alpha\) score for a proposed index via the cronbachs_alpha() function from the performance package.
# Behavior index
scale_data |>
select(persuade:contribute_money_group) |>
cronbachs_alpha()
# Positive Emotions
scale_data |>
select(hopeful, happy, proud) |>
cronbachs_alpha()
#Negative Emotions
scale_data |>
select(afraid, outraged, angry, worried, irritated, nervous) |>
cronbachs_alpha()- 1
-
Select the variables we want to obtain an \(\alpha\) score for. We separate column names via a : here because these columns are adjacent to one another in our data. We are thus telling R to select all columns between
persuadeandcontribute_money_group. If that were not the case, then we would have to separately identify the columns as in the other two examples.
[1] 0.6306181
[1] 0.8418678
[1] 0.9287744The \(\alpha\) scores for the two emotion scales are 0.84 and 0.93 respectively. This indicates that both scales are highly reliable. The reliability for the negative emotions scale is greater in large part due to the presence of more items. At this point we feel comfortable creating two separate scales based on these emotion items. The \(\alpha\) score for the behavior index, meanwhile, is lower at 0.63. This is below the often used 0.70 rule of thumb for judging a scale as being reliable. However, \(\alpha\) scores will be attenuated when the scale is comprised of binary variables, as we noted above. In our case, then, we feel comfortable using the scale of these items.
E.2.3 To Sum or to Average?
We will create three indices: one for campaign behavior and two for the emotions. The next question we confront is this: how should combine these items together? We could either sum the items in the index up or alternatively average them together. Which method should we use?
There is not necessarily a “right” answer to the foregoing question as the decision to sum vs. average will depend on the specifics of the items and your goals. Summing indicators makes more intuitive sense when the goal is to examine the total or count of something. Averaging, on the other hand, makes more sense when we want to maintain the original scaling of the items for our index. We could add up all of the emotion items above but this would lead to scales with different ranges (e.g., the negative emotions scale is based on six items and hence an additive scale would range from 6 to 30 while an additive positive emotions scale would range from 3 to 15). Averaging the items, meanwhile, would produce scores on a 1-5 scale for both indices and one that is easier to interpret. What would a score of 20 really represent on a summed scale of the negative emotion items? On the other hand, a 4 on a scale created by averaging the different emotion items together is a bit easier to interpret in this case (e.g., the person tends to say “very” to each of the questions).
Another consideration to think about concerns missing data and is particularly important when thinking about summative indices. When we tell R to take a mean or a sum of something we need to tell it how to handle missing data via na.rm = TRUE or na.rm = FALSE. The former command tells R to remove missing observations before performing the calculation while the latter tells R not to do that. We need to use na.rm = TRUE to calculate a mean or take a sum as otherwise the command will return “NA” as this example shows:
# Some data for the example
x <- c(5, 1, 2, NA, 5)
# Taking a mean
mean(x, na.rm = TRUE)[1] 3.25mean(x, na.rm = FALSE)[1] NAIf we form an index by averaging together multiple items, then the resulting average will be based only on those items for which you have data. If your index is created by taking the average of five items but an observation is missing data on one of the observations, then the index score for that observation will be based on the four items for which there is data. This is generally okay.
What if we are taking a sum? We again need to set na.rm = TRUE in order to obtain a non-NA outcome. However, we have to be careful here. When we use na.rm = TRUE with sum(), the command will work by giving a score of 0 to any observation with an NA value in order to calculate the final scale item for the observation. This can lead to some unintended effects if we have observations without any data on the variables used to calculate the scale. Consider this example where we create a dataset with two variables, x and y. The x column is entirely comprised of NA responses, while the y column has a single NA. We then take the sum of both columns.
# Toy data
data <- tibble(
x = c(NA, NA, NA, NA, NA),
y = c(0, 1, 0, 0, NA)
)
# Take a look
data# A tibble: 5 × 2
x y
<lgl> <dbl>
1 NA 0
2 NA 1
3 NA 0
4 NA 0
5 NA NA# Sum up the columns
data |>
mutate(sum_x = sum(x, na.rm = T),
sum_y = sum(y, na.rm = T))# A tibble: 5 × 4
x y sum_x sum_y
<lgl> <dbl> <int> <dbl>
1 NA 0 0 1
2 NA 1 0 1
3 NA 0 0 1
4 NA 0 0 1
5 NA NA 0 1The sum of the x column is 0…even though there is no actual data to sum. We are, in some sense, imputing data for this “case” in our data which could be quite problematic. The campaign engagement measures used in Example 1, for instance, were asked on the post-election wave of the ANES survey. However, not all respondents took part in the post-election survey. If we did not take that into account in some manner, then creating a summative indicator for campaign engagement would give each of those respondents a score of 0 on a scale to which they couldn’t even give a response! We filtered out those respondents from our dataset when creating it for this example, so we do not need to worry about this happening, but there may still be individuals in our dataset that completed the survey but nevertheless failed to answer all of the engagement items.6 We will show how to find these types of observations and how to deal with them below.
E.2.4 Creating the Scales
The basic tools needed to create an index in R are ones that you have encountered before: mean() and sum().7 If you have used these tools previously, then you have used them on one column at a time, e.g,. to find the mean or total of a single variable. Creating an index, however, requires us to combine multiple columns together. There are different ways we can accomplish this end but here will rely on some new commands that are part of the tidyverse: rowwise() and c_across(). These tools are meant for the types of operations we are going to perform below. You can learn more about these tools via the following vignette as well.
E.2.4.1 An Index via averaging
We’ll begin by creating two indices: one where we average together the three positive emotions items and one where we average together the six negative ones.
scale_data <- scale_data |>
rowwise() |>
mutate(
positive_emotions = mean(c(hopeful, happy, proud), na.rm = T),
negative_emotions = mean(c(afraid, outraged, angry, worried,
irritated, nervous), na.rm = T)) |>
ungroup()Here is how to read the syntax:
scale_data |> rowwise() |>-
The new command here is
rowwise(). The vignette linked to above provides a succint explanation for what this is doing: “If you usemutate()with a regular data frame, it computes the mean of x, y, and z across all rows. If you apply it to a row-wise data frame, it computes the mean for each row.” In other words, when we specifyrowwise(), we tell R to then perform subsequent operations on each row separately. mutate(positive_emotions = mean(c(hopeful, happy, proud), na.rm = T), ...))-
We then tell R to add new columns to our dataset via
mutate(). The first variable we are creating is to be namedpositive_emotions. This should be the product of themean()function. The main difference here from what you have seen elsewhere is thec(hopeful, happy, proud)andc(afraid, outraged, ..., nervous)entries. What we are doing here is telling R which columns in our dataset to average across. Finally,na.rm = Ttells R to ignore missing values when calculating the average. ungroup()-
This tells R to ungroup the data - to undo the
rowwise()element of the syntax. This is done to avoid accidentally doing future operations (e.g., futuremutate()commands) row-by-row.
Here is a glimpse at our data including the new columns:
scale_data |>
select(hopeful:negative_emotions) |>
head() |>
kable(digits = 2)- 1
- Automatically selects the first few rows of data for presentation.
- 2
-
kable()is a common tool for creating tables in html files. We use it here make sure all columns are shown to you.
| hopeful | afraid | outraged | angry | happy | worried | proud | irritated | nervous | positive_emotions | negative_emotions |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 | 5 | 5 | 1 | 5 | 1 | 5 | 5 | 1.00 | 5.00 |
| 2 | 4 | 3 | 3 | 2 | 3 | 1 | 3 | 3 | 1.67 | 3.17 |
| 3 | 5 | 4 | 4 | 2 | 5 | 3 | 4 | 5 | 2.67 | 4.50 |
| 3 | 4 | 2 | 3 | 3 | 4 | 4 | 4 | 4 | 3.33 | 3.50 |
| 2 | 5 | 5 | 4 | 1 | 5 | 2 | 5 | 5 | 1.67 | 4.83 |
| 5 | 1 | 1 | 1 | 4 | 1 | 5 | 1 | 1 | 4.67 | 1.00 |
The first respondent was very unhappy about the state of affairs in America: they gave a score of 1 on each positive emotion item (and hence have an average of 1 on the index) and a score of 5 on all negative ones (and hence an average of 5 on the index). Respondent 6 was nearly the exact opposite on this front while the other respondents shown in this output are somewhere in the middle.
We can get a sense of the inter-relationship between the scales by looking at their bivariate correlation:
cor.test(scale_data$positive_emotions,
scale_data$negative_emotions,
method = "pearson")
Pearson's product-moment correlation
data: scale_data$positive_emotions and scale_data$negative_emotions
t = -39.523, df = 4758, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.5182429 -0.4754587
sample estimates:
cor
-0.497153 The two items have a moderate negative correlation. However, the correlation is not a perfect one such that many respondents could perhaps be described as feeling “ambivalently” about the state of things in the US on the eve of the 2024 Presidential election (i.e., a mixutre of positive and negative emotions).
E.2.4.2 An Index via summing
A very similar process can be used to create summative indices in R. However, one thing we should first do is check to see if there are any observations with entirely missing data on the variables comprising the index that we want to create. We can do this as so (although, as we show you below, there is a simpler way to specify the variables in this command that would be useful here):
scale_data <- scale_data |>
rowwise() |>
mutate(engage_missing = sum(is.na(c(persuade, online_meetings, rallies,
campaign_button, other_work,
contribute_money_party,
contribute_money_group)))) |>
ungroup()sum(is.na(c(persuade, ..., contribute_money_group))))-
As above, we use
rowwise()followed by amutate()command. Here we are interested in counting how many observations are missing data on our 7 measures of campaign engagement so we use thesum()function. We specifically want to know if the observation has missing data. We use theis.na()function to accomplish this goal.is.na()here will essentially convert the columns in thec()portion of the command into binary variables where 0 = non-missing and 1 = missing data withsum()then finding the total.
We can next look to see if there are any observations with missing data on all 7 columns via a simple table() command:
table(scale_data$engage_missing)
0 1 3 4 6 7
4752 9 199 2 1 1 The vast majority of observations has full data (i.e., 0 missings). Only one observation has complete missing data on these items. We can filter this observation out of our data to make sure that we do not give it an inaccurate scale estimate later on:8
scale_data <- scale_data |>
filter(engage_missing < 7) We can finally turn to creating our index. Here we will introduce a handy shortcut that we can use here: c_across():
scale_data <- scale_data |>
rowwise() |>
mutate(campaign_engagement = sum(c_across(persuade:contribute_money_group))) |>
ungroup()campaign_engagement = sum(c_across(persuade:contribute_money_group)))-
Earlier we manually listed all of the columns we either wanted to average together or add together via
c(). This works, but can be a bit cumbersome if there are many columns to write out. We can instead simplify our life by telling R to sum together all columns in a sequence by separating the first column and the last with a colon (persuade:contribute_money_group). This will only make sense/work, though, if this sequence of columns does not include variables we don’t want in our index; if there were columns like that in the sequence (e.g., ifhopecame afterpersuadein our data), then they would also be included in the final scale. In those situations we can always use thec()method seen in earlier examples.
Let’s take a look at distribution of the final index:
table(scale_data$campaign_engagement)
0 1 2 3 4 5 6 7
2436 1345 504 257 120 60 19 11 The vast majority of respondents completed either 0 or 1 of the campaign activities. Only 11 respondents, meanwhile, took part in all 7 activities.
E.2.5 Let’s Run a Model!
Now that we have created our indices, we can of course analyse them with a regression model. Here we’ll perform a linear regression predicting the campaign engagement measures based on the two emotion indices:9
# Model
engagement_model <- lm(campaign_engagement ~ positive_emotions + negative_emotions,
data = scale_data)
# Coefficients
tidy(engagement_model)# A tibble: 3 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -0.648 0.0971 -6.68 2.68e-11
2 positive_emotions 0.320 0.0211 15.2 1.00e-50
3 negative_emotions 0.239 0.0188 12.7 1.73e-36There exists a positive, and statistically significant, relationship between both indices and campaign engaegment. ANES respondents that reported stronger emotional reactions to current events also tended to report engaging in more campaign behaviors than those with weaker ones and this occurs regardless of whether we are considering positive emotions such as hope as negative ones such as anger.
E.3 Example 2: Items with Different Scales
The scales we created above used items that had the same scaling (i.e., all binary items in the campaign engagement index or items that all ranged from 1 to 5 in the emotion indices). However, you might want to / need to create indices from items on very different scales. We’ll discuss how you can accomplish this end in the following sub-sections.
E.3.1 Two Approaches: Normalization and Standardization
Our second example will focus on a measure known as the human development index (HDI). The HDI index is “a summary measure of average achievement in key dimensions of human development: a long and healthy life, being knowledgeable and having a decent standard of living”. It is created by combining together country-level data: life expectancy in years, educational attainment (based on the expected years of schooling and the mean years of schooling achieved in the country), and country wealth via the natural logarithm of gross national income (GNI) per capita. This image is taken from the UN’s technical documentation regarding the report and summarizes the creation of HDI:
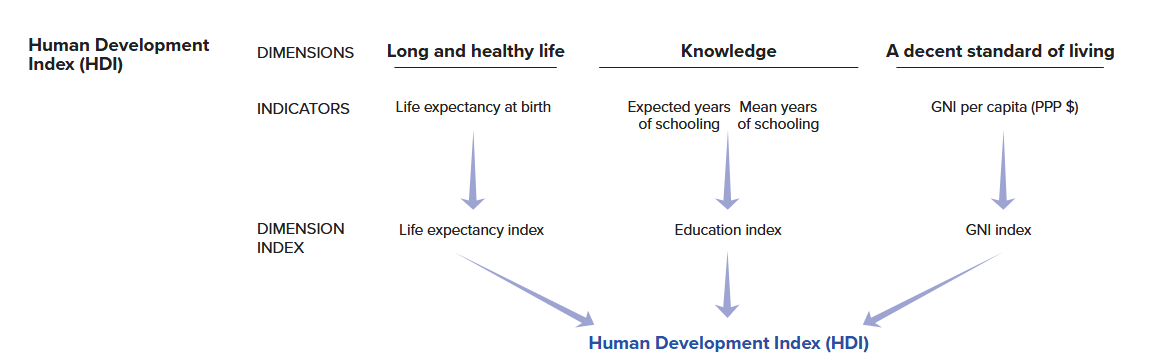
Our goal in the following sections is to create an HDI scale ourselves using the underlying data used by the UN for the year 2023, which we obtained from their website. Here is an overview of the four variables that are used to construct the HDI index: life expectancy at birth in years (life_expectancy), the expected years of schooling in the country in years (expected_schooling), the mean years of schooling in years (mean_schooling), and gross national income (which has been logged; gni_percap_logged):10
datasummary(life_expectancy + expected_schooling + mean_schooling + gni_percap_logged ~
Mean + SD + Min + Max + N, data = hdi_data)| Mean | SD | Min | Max | N | |
|---|---|---|---|---|---|
| life_expectancy | 73.11 | 7.16 | 54.46 | 85.00 | 193 |
| expected_schooling | 13.49 | 2.91 | 5.63 | 18.00 | 193 |
| mean_schooling | 9.17 | 3.19 | 1.41 | 14.30 | 193 |
| gni_percap_logged | 9.51 | 1.17 | 6.53 | 11.23 | 193 |
We can clearly see that the variables are on very different scales. Life expectancy ranges from 54 to 85, for instance, whereas the mean years of schooling achieved measure ranges from 1.41 to 14.30. As a result, if we simply averaged these variables together to create our scale we’d end up with a hard to understand index.
How can we create a meaningful index from these differently scaled items? In situations like this researchers will first rescale the variables in question to place them on the same scale before creating their index. There are two common tactics here: normalization and standardization.
Normalization involves rescaling variables so that they have the same minimum and maximum values. The following formula will rescale a variable to a 0-1 range where 0 = the minimum value on the original variable and 1 = the maximum value on the original variable. If we wanted to scale the variable to 0-10 (for instance), then we could simply multiply this output by 10.
\[\text{(0-1) Normalized Variable} = \frac{X_{i} - min(X)}{max(X) - min(X)}\] The HDI scale is created using a normalization process much like this although the UN sets the minimum and maximum values for some of the rescaled variables at pre-chosen values instead of the minimum and maximum values observed in the data. For instance, they rescale the life expectancy variable using this formula but use 20 and 85 as the minimum and maximum values in the equation. They do so because “no country in the 20th century had a life expectancy at birth of less than 20 years” and “85 [is] a realistic aspirational target for many countries over the last 30 years.” They do something similar for GNI per capita, setting a minimum of log($100) and a maximum of log($75000). They rescale their education variables in a simpler manner: they code all countries with either 18+ (expected schooling) or 15+ (mean years of actual schooling) years to 18 and 15 and then divide the variables by 18 and 15 respectively to normalize the variable. We will show you how to manually calculate normalized scales below using these values to maintain fidelity to the UN’s approach. We will also show you how to normalize variables using a command from the scales package (rescale()) that will automatically find the minimum and maximum values of a variables and which will be more generally useful.
Normalization is a common way of rescaling a variable whether we are simply using that variable as is in our regression model or we are combining it with other variables in a scale. Normalization has a few advantages. It makes sure that all (rescaled) variables have the same range. Importantly, it can also be used with different types of variables such as interval/ratio, ordinal, and binary variables. At the same time, normalization does not standardize the variance of the variables being combined together. This can have the consequence of variables with relatively less variance contributing less to an observation’s score on the final scale.
An alternative way approach would be to first standardize the variables in question before combining them together:
\[\text{Standardized Variable} = \frac{X_{i} - \bar{X}}{\text{Std. Dev}(X)}\]
Here, we subtract the mean of the variable from each observation and then divide by the standard deviation of the variable. The resulting standardized variable is centered at 0 with 0 indicating an average score on the original variable. Deviations from 0 are expressed in standard deviations. This standardizes the variation of all items thereby enabling them to contribute equally to the final index regardless of their original variance. However, it also changes the interpretation of values in an important sense. Suppose that a variable has a positive value on a standardized variable. This tells us that the observation has an above average score on this variable. However, it is possible that the average value of the originating variable is actually quite low such that “above average” doesn’t equate to having a “high” value in terms of the original scaling of the variable. Regardless, standardization can be a powerful way of creating indices from items with different scales and especially so with interval/ratio variables.
E.3.2 Creating and Investigating the Indices
We’ll create versions of the HDI index using both normalization and standardization in the sections below. We’ll then compare the two measures against one other to see how they are alike and how they differ.
E.3.2.1 Normalization
HDI is calculated by averaging together three normalized variables: life-expectancy, the average of the two education measures discussed above, and the log of GNI per capita. We will show you how to normalize variables manually, using the formula shown earlier, and using the rescale() command from the scales packake. This latter approach is what we would generally recommend taking, but we also want to show the manual approach to show the underlying process and to be as faithful as possible to the specific methods used by the UN in creating this scale.
The first step we will take is finding the average of the two education measures used in calculating HDI. The UN first divides the measures by 18 and 15 respectively to create a 0-1 scaling and then takes the average of the two items. We accomplish this via the syntax shown below which uses the same rowwise() technique from above to find the average of the two variables.
# Create the education index for use later on
hdi_data <- hdi_data |>
mutate(
expected_yrs_rescale1 = expected_schooling / 18,
mean_yrs_rescale1 = mean_schooling / 15) |>
rowwise() |>
mutate(
education_index_1 = mean(c(expected_yrs_rescale1, mean_yrs_rescale1), na.rm = T)
) |>
ungroup()
# Check the distribution
summary(hdi_data$education_index_1) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2491 0.5567 0.7130 0.6806 0.8280 0.9636 # Look at the data
hdi_data |>
select(expected_schooling, expected_yrs_rescale1,
mean_schooling, mean_yrs_rescale1,
education_index_1) |>
slice_head(n = 5) |>
kable(digits = 2)| expected_schooling | expected_yrs_rescale1 | mean_schooling | mean_yrs_rescale1 | education_index_1 |
|---|---|---|---|---|
| 18.00 | 1.00 | 13.91 | 0.93 | 0.96 |
| 18.00 | 1.00 | 13.12 | 0.87 | 0.94 |
| 16.67 | 0.93 | 13.95 | 0.93 | 0.93 |
| 18.00 | 1.00 | 13.03 | 0.87 | 0.93 |
| 17.31 | 0.96 | 14.30 | 0.95 | 0.96 |
The final index variable ranges from 0-1 with a minimum of 0.25 and a maximum of 0.96. We can follow the calculation of the index by looking at the relevant variables in the dataset. The first observation shows the maximum of 18 years of expected education. If we divide this by 18, then we get the maximum value of 1 on expected_yrs_rescale1. However, this observation does not have the maximum value on mean_schooling, but instead 13.9. If we divide this number by 15, then we get a value close to the maximum of 1: 0.93. The average of 1 and 0.93 can be found under education_index_1.
Our next step will be to normalize the life-expectancy and (log of) GNI per capita measures. The UN uses custom minimum and maximum values in doing so: 20 and 85 for life expectancy and log(100) and log(75000) for GNI per capita.
# Normalize these variables
hdi_data <- hdi_data |>
mutate(
life_rescale1 = (life_expectancy - 20) / (85 - 20),
gni_rescale1 = (gni_percap_logged - log(100)) / (log(75000) - log(100)))
# Check the distributions
summary(hdi_data$life_rescale1) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.5302 0.7290 0.8229 0.8170 0.8976 1.0000 summary(hdi_data$gni_rescale1) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2914 0.6120 0.7654 0.7407 0.8924 1.0000 When normalizing the variables we subtracted the UN supplied minimum value from each obervation’s value on the variable and then divided this value by the difference between the UN supplied maximum and minimum values. We can see from the output of the summary() command that we have now put these variables on a scale ending in 1, although here the minimum values are not 0 exactly.
Finally, we can create our index by averaging these together using the same tools (rowwise() and mean(c(), na.rm =T)) as earlier.11
# Create the scale
hdi_data <- hdi_data |>
rowwise() |>
mutate(hdi_normalize_un = mean(c(life_rescale1, gni_rescale1,
education_index_1), na.rm = T)) |>
ungroup()
# Its distribution
summary(hdi_data$hdi_normalize_un) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.4059 0.6298 0.7646 0.7461 0.8620 0.9719 Our final scale ranges from 0.41 to 0.97 with higher values indicating higher levels of educational attainment, country wealth, and life expectancy.
The process above used custom minimum and maximum values from the UN. The UN justifies these values based on theoretical considerations. In your own examples, though, it will be simpler to use (and justify) the actual observed minimum and maximum values for the variables in your dataset rather than specifying (potentially arbitrary) values of your own. Here, we can use the scales::rescale() command to accomplish our goals. We will first normalize all four variables using this method before creating the final scale.
hdi_data <- hdi_data |>
mutate(
expected_yrs_rescale2 = scales::rescale(expected_schooling, to = c(0,1)),
mean_yrs_rescale2 = scales::rescale(mean_schooling, to = c(0,1)),
life_rescale2 = scales::rescale(life_expectancy, to = c(0,1)),
gni_rescale2 = scales::rescale(gni_percap_logged, to = c(0,1)))- 1
-
We use the prefix here (
scales::) so that we can use this function without loading the library in question. Thescaleslibrary is great, but it can conflict with other libraries in use in our document. Otherwise, we could simply loadscalesfirst and then our other packages.
Here is how to read the syntax.
scales::rescale(-
The syntax here has a common structure so we will simpy focus on this first example. The name of the command is
rescale()although we include a prefix here (scales::) to tell R that we want to use this command without loading the library (scales) in question. We do this to avoid potential conflicts with other packages. expected_schooling, to = c(0,1))-
We next provide the name of the variable we want to rescale. We end with
to = c(0,1). This tells the command that we want to rescale th evariable to a 0-1 interval. We could specify other values as well (e.g.,c(0,10)would scale to a 0-10 interval).
Let’s take a quick look at the original life expectancy measure and how the two rescaled versions relate to it and to each other:
# Original and UN measure
p1 <- ggplot(hdi_data, aes(x = life_expectancy, y = life_rescale1)) + geom_point() +
scale_y_continuous(limits = c(0,1)) +
labs(title = "Normalization using UN\nprovided min(x) and max(x)")
# Original and scales::rescale()
p2 <- ggplot(hdi_data, aes(x = life_expectancy, y = life_rescale2)) + geom_point() +
labs(title = "Normalization via\nscales::rescale()")
# Combined plot using the patchwork library
p1 + p2 - 1
-
\nhere adds a linebreak to the title.
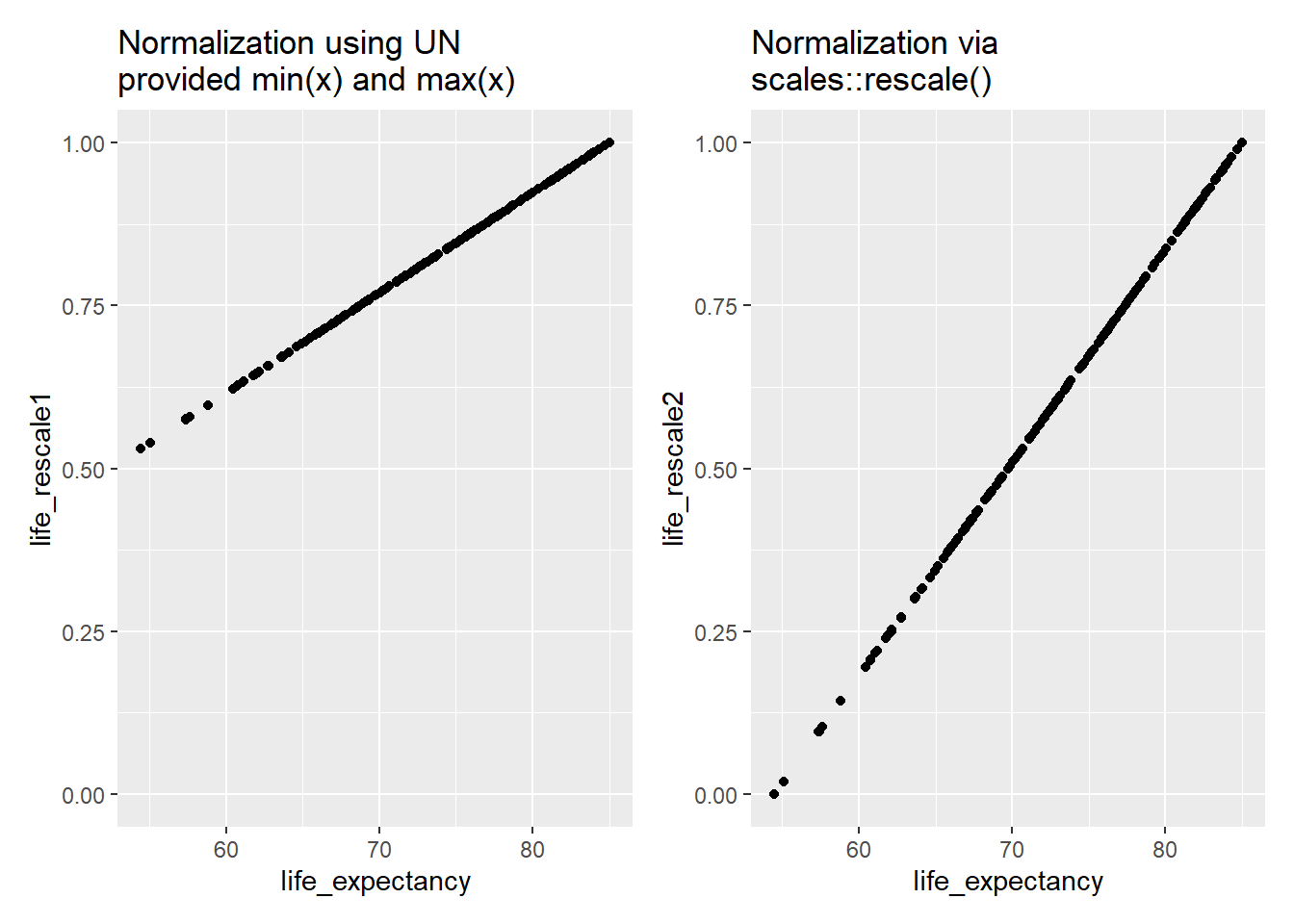
Both normalized variables range between 0 and 1. However, we can see that the minimum value of the variable we created using scales::rescale() is exactly 0 while the minimum for the version created using the UN’s rules is higher at just north of 0.5 (0.53). Why did this happen? scales::rescale() will use the observed minimum and maximum values of the variable in the dataset when normalizing. An observation with the minimum observed value on the variable being rescaled will have a value of 0 on the new variable while one with the maximum observed value will have a score of 1 as we can see from the plot on the right. The UN approach set the minimum values for life expectancy and GNI per capita at specific values that do not match the actual observed minimums in the dataset. The actual observed minimum for life expectancy, for instance, is 54.26 rather than the UN supplied 20. This leads to higher values at the lower end of the scale.
Returning to our scales::rescale() normalized variables, we can finally create the index much as above:
# Creating the index using the scales::rescale() normalized variables
hdi_data <- hdi_data |>
rowwise() |>
mutate(
education_index_2 = mean(c(expected_yrs_rescale2, mean_yrs_rescale2), na.rm = T),
hdi_normalize_scales = mean(c(education_index_2, life_rescale2, gni_rescale2), na.rm = T)
) |>
ungroup()How does this scale compare to the version using the UN supplied values?
# Comparing the two versions
summary(hdi_data$hdi_normalize_scales) # scales::rescale() normalization Min. 1st Qu. Median Mean 3rd Qu. Max.
0.09029 0.44718 0.65276 0.62116 0.80117 0.96629 summary(hdi_data$hdi_normalize_un) # normalization using UN provided values Min. 1st Qu. Median Mean 3rd Qu. Max.
0.4059 0.6298 0.7646 0.7461 0.8620 0.9719 # Correlation
cor.test(x = hdi_data$hdi_normalize_un,
y = hdi_data$hdi_normalize_scales,
method = 'pearson')
Pearson's product-moment correlation
data: hdi_data$hdi_normalize_un and hdi_data$hdi_normalize_scales
t = 240.73, df = 191, p-value < 2.2e-16
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.9978160 0.9987628
sample estimates:
cor
0.9983561 The two scales both range continuously between 0 and 1 although the values are not exactly identical given the use of different minimum and maximum values in the normalization process. The UN version leads to higher values at the lower end of the scale because the observed minmum values in the dataset are larger than the UN supplied minimums. Even so, the two scales correlate at 0.998, so these differences are unlikely to matter much when we use them in our statistical models.
E.3.2.2 Standardization
We standardize a variable by subtracting the mean of the variable from an observation and then dividing that value by the variable’s standard deviation. We can use the scale() command to accomplish this goal. This command is built into R, so you do not need to load a library to use it.
# Standardizing
hdi_data <- hdi_data |>
mutate(
life_std = scale(life_expectancy, center = TRUE, scale = TRUE),
expected_yrs_std = scale(expected_schooling, center = TRUE, scale = TRUE),
mean_yrs_std = scale(mean_schooling, center = TRUE, scale = TRUE),
gni_std = scale(gni_percap_logged, center = TRUE, scale = TRUE)
)Here is how to read the syntax:
scale(-
The name of the command is
scale(). life_expectancy, center = TRUE, scale = TRUE)-
We then provide the name of the variable we want to standardize. We further tell the command to center the variable (subtract the mean from each observation) via
center = TRUEand to standardize it by dividing by the standard deviation viascale = TRUE.
Let’s take a look at the properties of the resulting variables:
# Take a look
hdi_data |>
select(life_std, expected_yrs_std, mean_yrs_std, gni_std) |>
psych::describe() vars n mean sd median trimmed mad min max range skew
life_std 1 193 0 1 0.05 0.04 1.17 -2.61 1.66 4.27 -0.29
expected_yrs_std 2 193 0 1 -0.05 0.05 1.10 -2.70 1.55 4.25 -0.34
mean_yrs_std 3 193 0 1 0.24 0.07 1.13 -2.44 1.61 4.04 -0.52
gni_std 4 193 0 1 0.14 0.05 1.20 -2.54 1.47 4.01 -0.37
kurtosis se
life_std -0.71 0.07
expected_yrs_std -0.51 0.07
mean_yrs_std -0.72 0.07
gni_std -0.80 0.07We can see that all variables now have a mean of 0 and a standard deviation of 1. Their min and max values are not identical, but the values on these standardized variables have the same meaning (i.e., how much does the observation differ from the average).
Finally, we will create our index by simply averaging the four values together:
# Create the scale
hdi_data <- hdi_data |>
rowwise() |>
mutate(
hdi_standardized = mean(c(life_std, expected_yrs_std,
mean_yrs_std, gni_std),
na.rm = T))
# Take a look at its values
summary(hdi_data$hdi_standardized) Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.12111 -0.73406 0.09892 0.00000 0.75342 1.44253 The resulting scale ranges from -2.12 to 1.44 with an average or mean value of 0. Observations near the maximum of this scale will have above average scores on all (or nearly all) of the items that were the basis for the resulting scale.
E.4 References
Adcock, Robert, and David Collier. 2001. “Measurement Validity: A Shared Standard for Qualitative and Quantitative Research.” American Political Science Review 95 (3): 529–46.
Brady, Henry E, Sidney Verba, and Kay Lehman Schlozman. 1995. “Beyond SES: A Resource Model of Political Participation.” American Political Science Review 89 (2): 271–94. https://doi.org/10.2307/2082425.
Castanho Silva, Bruno, Sebastian Jungkunz, Marc Helbling, and Levente Littvay. 2020. “An Empirical Comparison of Seven Populist Attitudes Scales.” Political Research Quarterly 73 (2): 409–24. https://doi.org/10.1177/1065912919833176.
Marcus, George E, and Michael B Mackuen. 1993. “Anxiety, Enthusiasm, and the Vote: The Emotional Underpinnings of Learning and Involvement During Presidential Campaigns.” The American Political Science Review 87 (3): 672–85. https://www.jstor.org/stable/2938743.
Valentino, Nicholas A, Ted Brader, Eric W Groenendyk, Kysha Gregorowicz, and Vincent L Hutchings. 2011. “Election Night’s Alright for Fighting: The Role of Emotions in Political Participation.” The Journal of Politics 73 (1): 156–70.
Vasiopoulos, Pavlos, George E. Marcus, Nicholas A. Valentino, and Martial Foucault. 2019. “Fear, Anger, and Voting for the Far Right: Evidence from the November 13, 2015 Paris Terror Attacks.” Political Psychology 40 (4): 679–704.
Young, Lauren E. 2019. “The Psychology of State Repression: Fear and Dissent Decisions in Zimbabwe.” American Political Science Review 113 (1): 140–55.
See Castanho Silva et al. (2020) for a discussion of different populism scales.↩︎
See, for instance, Adcock and Collier (2001) for a deeper treatment of the concepts discussed here.↩︎
See Brady, Verba, and Schlozman (1995) for a classic account of the role of skills and resources in understanding political participation. Our focus on emotions is inspired by Valentino et al. (2011) who examine motivation and campaign engagement in the US using data from an earlier ANES survey. Of course, emotions may also demobilize people as Young (2019) shows in her study of emotions and state repression in Zimbabwe.↩︎
See Marcus and Mackuen (1993) for the early landmark study on this front. Subsequent work, including Valentino et al. (2011), further divides the negative emotion dimension into two: one pertaining to “anxiety” (e.g., feeling “afraid”) and the other to “aversion” (e.g., feeling “angry”). Measurements of these two emotional states are often highly correlated although sometimes they are more clearly differentiated (e.g., some people might feel much more angry than afraid after a political event while others might feel much more afraid than angry). In such cases it can be important to clearly differentiate between anger and anxiety as they can have distinct political effects; see Vasiopoulos et al. (2019) for an example.↩︎
A more specific formula is: \(\alpha = \frac{k\bar{c}}{\bar{v} + (k - 1)\bar{c}}\). \(k\) = the number of items. \(\bar{v}\) = the average variance of the items. \(\bar{c}\) = the average covariance between the items.↩︎
Respondents could refuse to answer the engagement questions or say they “don’t know” as well. These respondents are coded as missing. If a respondent refused to answer all items, for instance, then they would be missing on all measures.↩︎
You shouldn’t try and create an index by manually adding together or averaging together columns (e.g.,
newvar = var1 + var2 + var3). This can work if there is no missing data at all in the dataset, but soon breaks down in more realistic situations where observations have missing values on one or more of the variables that are being combined together.↩︎An alternative here might be to use the
complete.cases()command much as one does when using theanova()command to compare models (as seen in Section 6.2). This would get rid of all observations with complete missing data. It would also remove the obervations with some (but not complete) missing data as well (e.g., those observations where data is missing on one or two items). We opted for this approach to keep as much data in our model as possible. In doing so we are, in essence, assuming that someone with missing data on a single item has not done this action. Note that the approach here could also be useful for restricting the construction of the scale to only those observations with a certain number of non-missing values. For instance, we could filter out observations with missing data on 4 or more of these variables before creating our scale.↩︎OLS models are not necessarily the most appropriate statistical model for analyzing count data such as this. However, the more appropriate models (poisson regression and negative binomial models) are beyond the scope of this book and an OLS regression will work just fine in a pinch.↩︎
The UN first takes some data cleaning steps before calculating the HDI index that we also performed when creating this datafile. For instance, the life expectancy variable was recoded such that countries with a life expectancy greater than 85 years were given a score of 85 and those with a GNI below 100 were given a value of 100 before taking the natural logarithm. If you would like to know more about the reasoning behind these recoding decisions, then we recommend the Technical Notes document that you can find on the documentation page for this measure as well as their “Calculating the Indices” tool (also provided on this webpage).↩︎
We are using the simple average of these items here, but the UN uses the geometric mean of the values so our final results do not exactly match the UN’s HDI calculation. The
psychpackage has a function for calculating the geometric mean.↩︎